

Driving Digital Performance for a Digital Media Brand
Headless CMS scales and improves WPWhiteBoard’s content distribution, flexibility, and personalization
Ankita Deb
If you're looking to programmatically interact with the content in your Storyblok space, you've come to the right place.
The Storyblok Management API is your primary tool for managing content—think creating, updating, deleting, or even restructuring your content and components. It’s the engine that powers content operations behind the scenes.
At its heart, the Storyblok Management API is built on REST principles, which makes it predictable and easy to work with. It uses resource-oriented URLs, accepts form-encoded request bodies, and returns JSON-encoded responses, which is a standard you're likely familiar with.
It's crucial to understand the distinction between the Management API and its counterpart, the Content Delivery API (CDA).
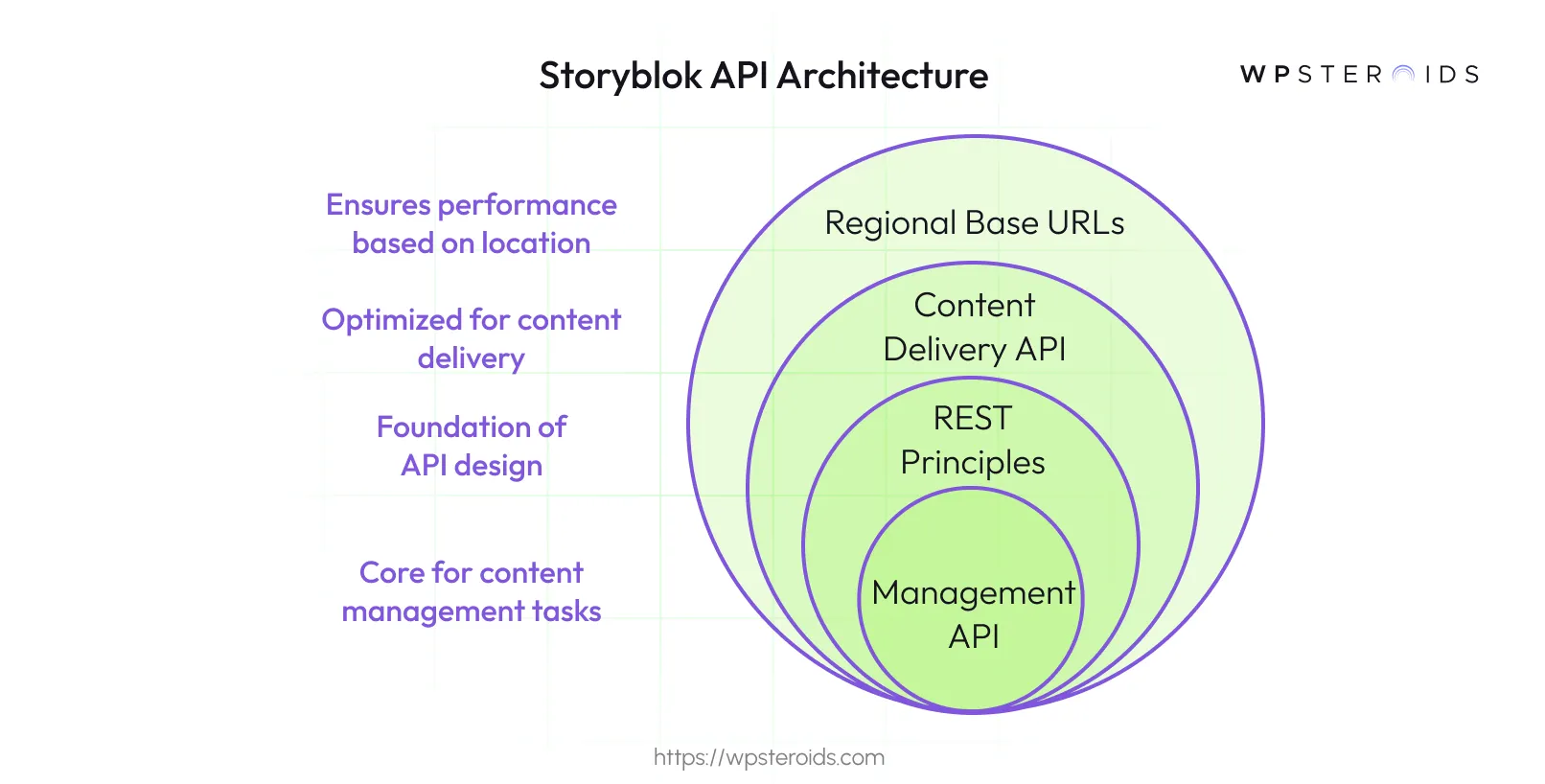
While the Management API is your go-to for all content management tasks (creating, editing, and deleting), it should not be used for delivering content to your live website or application.
For that, you should always use the Content Delivery API, which is highly optimized for fast, scalable, and read-only content delivery. Think of it this way: you use the Management API to stock and organize the warehouse, and the Content Delivery API for the storefront.
Finally, when you start making requests, you'll need to use the correct base URL for your space's region.
Storyblok hosts data in several locations to ensure better performance, so you will need to prefix your API calls with the appropriate URL, such as https://mapi.storyblok.com/v1/ for the US or https://mapi-eu.storyblok.com/v1/ for the EU.
The best way to understand an API is to use it. The official documentation introduces the concepts, but let's bridge the gap and walk through a "Hello World" tutorial that takes you from getting your credentials to making a successful API call.
For this example, we'll use Node.js to fetch a list of stories from our space.
First, you need a way to authenticate your requests. A Personal Access Token is perfect for this.
Next, let's create a simple project environment. Open your terminal and run the following commands:
mkdir storyblok-api-test
cd storyblok-api-test
npm init -y
npm install axios
touch index.jsThis creates a new directory, initializes a Node.js project, installs axios (a popular library for making HTTP requests), and creates an index.js file for our code.
Now, open index.js in your code editor and paste the following snippet. Make sure to replace 'YOUR_PERSONAL_ACCESS_TOKEN' with the token you copied and 'YOUR_SPACE_ID' with the ID of the space you want to access (you can find this in your Storyblok space settings).
// index.js
const axios = require('axios');
// Replace these with your actual token and space ID
const personalAccessToken = 'YOUR_PERSONAL_ACCESS_TOKEN';
const spaceId = 'YOUR_SPACE_ID';
// The URL for the Storyblok Management API
// Make sure to use the correct regional URL for your space, e.g., mapi-eu.storyblok.com
const apiUrl = `https://mapi.storyblok.com/v1/spaces/${spaceId}/stories`;
async function fetchStories() {
console.log('Attempting to fetch stories...');
try {
const response = await axios.get(apiUrl, {
headers: {
'Authorization': personalAccessToken, // The token is sent in the Authorization header
'Content-Type': 'application/json'
}
});
console.log('Successfully fetched stories!');
console.log(response.data); // Log the response data from the API
} catch (error) {
console.error('An error occurred:');
// Axios wraps the error response, so we log error.response.data for more details from the API
console.error(error.response ? error.response.data : error.message);
}
}
fetchStories();To run the script, save the file and execute the following command in your terminal:
node index.jsIf everything is configured correctly, you'll see a success message followed by a JSON object containing the stories in your space.
Congratulations, you've just successfully used the Storyblok Management API!
So far, we've covered the what and the how of the Management API's fundamentals. Now, let's get to the really exciting part: putting it into practice.
The true power of the Management API is unlocked when you use it to automate complex tasks, streamline workflows, and build custom tools that perfectly fit your team's needs.

Manual, repetitive tasks are prone to human error and consume valuable time. By scripting these operations with the Management API, you can make them faster, more reliable, and completely hands-off.
One of the most common one-off tasks you might face is migrating a large amount of content from another system into Storyblok. The idea of manually copying and pasting hundreds or thousands of articles is daunting, but with a simple script, we can automate the entire process.
For this guide, we'll write a Python script that reads content from a CSV file and creates new stories in Storyblok.
Step 1: Export Your Data to a CSV File
First, get your content out of your legacy system and into a structured CSV file. Let's assume your file, articles.csv, looks like this:
title, author, content_body
"My First Post","John Doe","<p>This is the body of my first post.</p>"
"Another Great Article","Jane Smith","<p>Here is some more interesting content.</p>"Step 2: Write the Migration Script
# migration_script.py
import requests
import json
import csv
import time
# --- Configuration ---
PERSONAL_ACCESS_TOKEN = 'YOUR_PERSONAL_ACCESS_TOKEN'
SPACE_ID = 'YOUR_SPACE_ID'
# Use the correct regional URL for your space
BASE_URL = f'https://mapi.storyblok.com/v1/spaces/{SPACE_ID}/stories/'
HEADERS = {
'Authorization': PERSONAL_ACCESS_TOKEN,
'Content-Type': 'application/json'
}
# The rate limit for your plan (e.g., 6 calls per second for Growth)
# Starter plans have a rate of 3 calls per second.
RATE_LIMIT_PER_SECOND = 6
SLEEP_TIME = 1.0 / RATE_LIMIT_PER_SECOND
# --- Script ---
def migrate_stories():
print("Starting content migration...")
with open('articles.csv', mode='r') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
story_title = row['title']
# This is where you transform your old data into the Storyblok schema.
# We assume you have a 'post' component with 'title', 'author', and 'body' fields.
story_payload = {
"story": {
"name": story_title,
"slug": story_title.lower().replace(' ', '-'),
"content": {
"component": "post",
"title": story_title,
"author": row['author'],
"body": row['content_body'] # This could be a rich-text field
}
},
"publish": 1 # Use 1 to publish immediately, or 0 to save as a draft
}
try:
print(f"Creating story: {story_title}")
response = requests.post(BASE_URL, headers=HEADERS, data=json.dumps(story_payload))
# Raise an exception for bad status codes (4xx or 5xx)
response.raise_for_status()
print(f"Successfully created '{story_title}'")
except requests.exceptions.HTTPError as err:
print(f"Error creating story '{story_title}': {err.response.text}")
# Be a good API citizen and respect the rate limit!
time.sleep(SLEEP_TIME)
print("Content migration finished.")
if __name__ == '__main__':
migrate_stories()This script reads each row from the CSV, constructs a JSON payload that matches our Storyblok "post" component, and sends it to the Management API. Crucially, it includes time.sleep().
This pauses the script briefly after each call to ensure we don't exceed the API rate limits (3 calls/second for the Starter plan; 6 calls/second for Growth and higher plans), preventing our requests from being rejected.
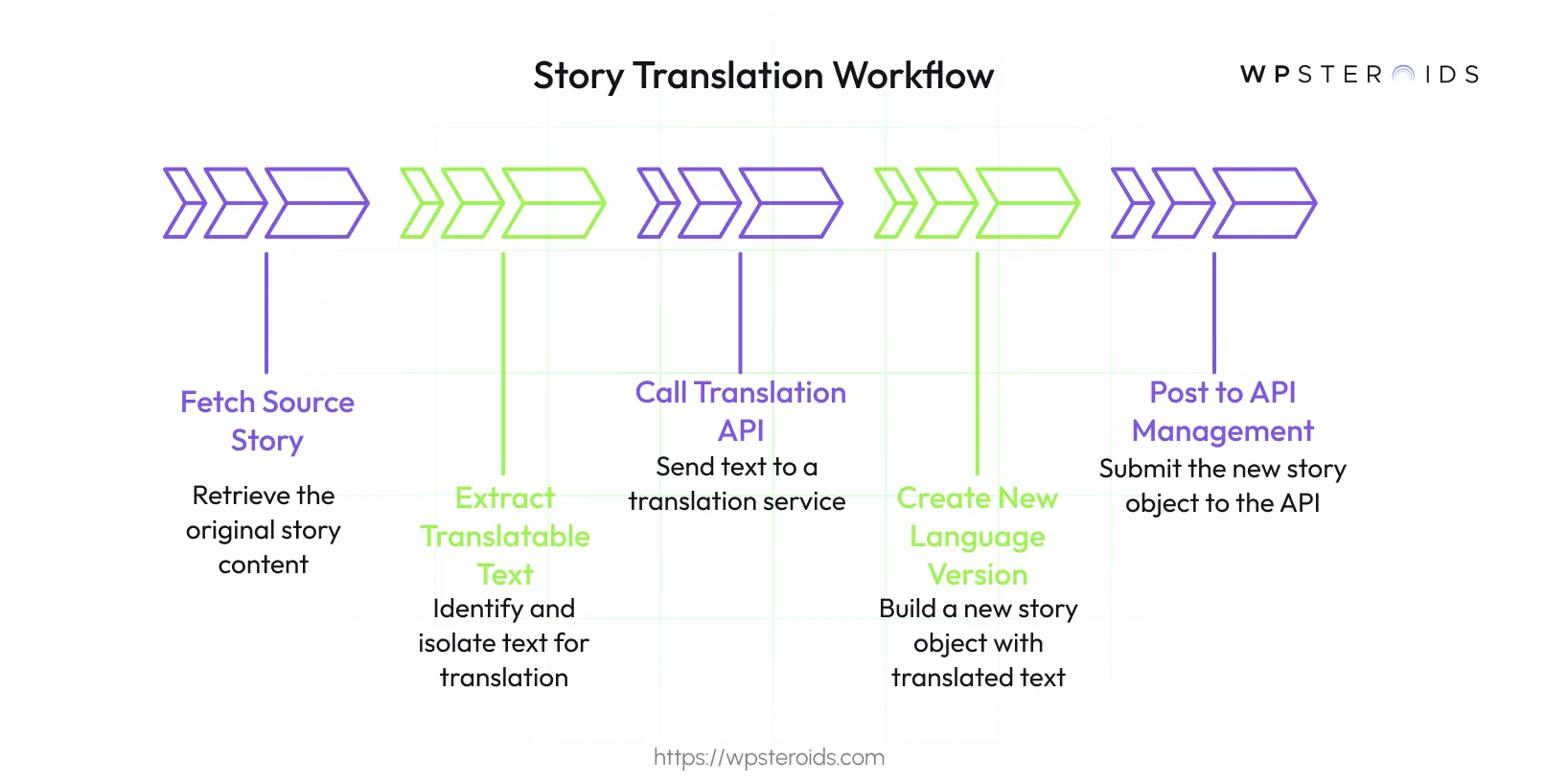
If you manage content in multiple languages, the API can save you from an enormous amount of copy-paste work. You can create a script that takes an existing story, sends its content to a translation service, and then creates a new story version for the target language.
The logical workflow would be:
Beyond one-off workflows, you can use the Management API to build permanent tools and integrations for your team.
Here are a few ideas to get you started:
You can also integrate Storyblok with other services you use. For example, you could use a Storyblok webhook to trigger a serverless function whenever a story's status is changed to "Ready for review."
This kind of integration connects your content operations directly into your team's existing project management workflow.
When you're writing code to interact with any API, things will inevitably go wrong. A network connection might drop, a token might be invalid, or the data you send might not be quite right. The mark of a robust application is how well it handles these errors.
Storyblok's Management API helps you by using standard HTTP status codes and, more importantly, by returning detailed JSON error messages.
While a 2xx status code (like 200 OK or 201 Created) means your request was successful, a 4xx code indicates a problem with your request, and a 5xx code signals a problem on Storyblok's end.
The 4xx errors are the ones you'll encounter most often, so it's vital to understand them. The original documentation lists the codes, but here we’ll pair them with the kind of JSON response you can expect, which is essential for writing your error-handling logic.
| HTTP Status Code | Meaning | Example JSON Response |
|---|---|---|
| 400 Bad Request | A generic error indicating that the server could not understand your request, often due to malformed syntax. | {"error": "Invalid request"} |
| 401 Unauthorized | Your request lacks valid authentication credentials. This means you either didn't provide a token or the one you provided is incorrect. | {"error": "Unauthorized"} |
| 403 Forbidden | You are authenticated, but you do not have permission to perform the requested action. Your token is valid, but its permissions are insufficient. | {"error": "You are not authorized to perform this action"} |
| 404 Not Found | The specific resource you're trying to access (like a story with a specific ID) does not exist. | {"error": "The resource you were looking for could not be found."} |
| 422 Unprocessable Entity | The server understands your request, but the data you sent violates a validation rule. This is a very common and informative error. | {"messages": {"slug": ["has already been taken"]}, "message": "Slug has already been taken"} |
| 429 Too Many Requests | You have exceeded the API rate limit for your plan. Storyblok limits how many requests you can make in a given period to ensure service stability. | {"error": "Too Many Requests"} |
Knowing what an error means is one thing; knowing how to fix it is another. Here are some practical steps to take for the most common issues.
This is almost always an issue with your Personal Access Token or OAuth token. Run through this checklist:
This error is your friend. It's telling you that the data in your request payload is the problem.
This means you're a victim of your own success—you're making calls too fast! The API rate limit is 3 calls/second for the Starter plan and 6 calls/second for higher-tier plans. While a simple time.sleep() works for basic scripts, the professional solution is to implement a retry mechanism with exponential backoff.
This strategy retries a failed request after a waiting period, and if the request fails again, it doubles the waiting period before the next retry, and so on. This prevents you from hammering the server while gracefully handling rate limiting.
Here is a JavaScript example showing how to wrap an axios call with this strategy:
// A function to wrap an API call with exponential backoff
async function callWithRetry(apiCall, maxRetries = 5) {
let attempt = 0;
while (attempt < maxRetries) {
try {
// Attempt the API call
const response = await apiCall();
return response; // Success! Return the response.
} catch (error) {
// Check if it's a rate limit error
if (error.response && error.response.status === 429) {
attempt++;
if (attempt >= maxRetries) {
console.error('Max retries reached. Aborting.');
throw error; // Rethrow the error after all retries fail
}
// Calculate the backoff time: (2^attempt) * 100ms
const delay = Math.pow(2, attempt) * 100 + Math.random() * 100; // Add jitter
console.warn(`Rate limit hit. Retrying in ${Math.round(delay)}ms... (Attempt ${attempt})`);
// Wait for the calculated delay
await new Promise(resolve => setTimeout(resolve, delay));
} else {
// If it's another type of error, rethrow it immediately
throw error;
}
}
}
}
// Example usage:
// const myApiCall = () => axios.post(apiUrl, payload, { headers });
// await callWithRetry(myApiCall);By proactively handling these errors, you can build applications that are more resilient, reliable, and user-friendly.
Once you've mastered the basics of creating and updating content, you'll inevitably run into larger-scale challenges. How do you retrieve thousands of stories without overwhelming the API?
How can you get a high-level overview of all the spaces and users in your account? This is where understanding pagination and the organization-level endpoints becomes essential for building truly powerful and scalable applications.
If your Storyblok space has more than a handful of stories, assets, or other resources, the Management API won't return them all in a single request.
Instead, it breaks the results into "pages" to ensure fast and reliable performance. To retrieve a complete dataset, you need to make requests for each page.
The API controls this using two simple query parameters:
To figure out how many pages you need to fetch, the API kindly provides a Total value in the response headers of your request.
This tells you the total number of items available. You can use this to calculate the total number of pages: totalPages = Math.ceil(total / per_page).
While the documentation explains these parameters, a code example makes the process much clearer. Let's write a JavaScript function to fetch all stories from a space, handling pagination automatically.
const axios = require('axios');
// --- Configuration ---
const PERSONAL_ACCESS_TOKEN = 'YOUR_PERSONAL_ACCESS_TOKEN';
const SPACE_ID = 'YOUR_SPACE_ID';
const PER_PAGE = 100; // Request the max number of items per page to minimize API calls
const BASE_URL = `https://mapi.storyblok.com/v1/spaces/${SPACE_ID}/stories`;
const api = axios.create({
baseURL: BASE_URL,
headers: {
'Authorization': PERSONAL_ACCESS_TOKEN
}
});
/**
* Fetches all stories from a Storyblok space, handling pagination automatically.
*/
async function fetchAllStories() {
console.log('Fetching all stories...');
let allStories = [];
// First, get the first page to find out the total number of stories
const firstPageResponse = await api.get(`?per_page=${PER_PAGE}&page=1`);
allStories = firstPageResponse.data.stories;
// Get the total number of items from the response header
const totalItems = parseInt(firstPageResponse.headers['total'], 10);
const totalPages = Math.ceil(totalItems / PER_PAGE);
console.log(`Found ${totalItems} stories across ${totalPages} pages.`);
if (totalPages <= 1) {
return allStories;
}
// Create an array of promises for the remaining pages
const pagePromises = [];
for (let page = 2; page <= totalPages; page++) {
pagePromises.push(api.get(`?per_page=${PER_PAGE}&page=${page}`));
}
// Fetch all remaining pages in parallel
const responses = await Promise.all(pagePromises);
// Add the stories from the other pages to our array
responses.forEach(response => {
allStories.push(...response.data.stories);
});
console.log(`Successfully fetched all ${allStories.length} stories.`);
return allStories;
}
// Example usage:
// fetchAllStories().catch(console.error);This script is much more efficient than requesting pages one by one. It makes one initial request to get the total count and then fires off parallel requests for all remaining pages, significantly speeding up the process for large datasets.
While most of your work will happen within a specific space, the Management API also provides an endpoint to get high-level information about your entire organization.
This is useful for administrative oversight and reporting. The primary endpoint for this is /orgs/me.
The official documentation shows an example response but doesn't explain what the fields mean, so let's fill in that gap. Here is a breakdown of the key fields you'll find in the response:
| Field | Explanation |
|---|---|
| id | A unique numerical ID for your organization. |
| name | The display name of your organization. |
| role | Your role within the organization (e.g., 'admin', 'member'). |
| plan | The human-readable name of your subscription plan (e.g., 'Growth'). |
| plan_level | A numerical identifier for the plan, used internally by Storyblok. |
| spaces_count | The total number of spaces that exist within this organization. |
| users | An array of user objects associated with your organization. Each object contains details like the user's id, email, and last_sign_in_at timestamp. |
| owners | An array of user objects specifically for those who have owner-level permissions in the organization. |
| collaborators | A count of all unique collaborators across all spaces in your organization. This can be higher than the number of users if a user is in multiple spaces. |
| sso | An object containing details about Single Sign-On configuration, if it is enabled for your organization. |
It is important to note that the current documentation primarily details this "read-only" /orgs/me endpoint.
As of now, endpoints for programmatically managing the organization itself (such as creating a new space directly under the organization or inviting a user at the org level via the API) are not explicitly documented.
Those management tasks are typically handled through space-specific endpoints (e.g., creating stories within a space).
At the end of the day, the Storyblok Management API provides a powerful set of building blocks. We've shown you how to put them together for common scenarios like data migration and error handling, but their ultimate purpose is for you to build your solutions.
No one understands your team's specific pain points and opportunities better than you do. So, take these concepts, fire up your code editor, and start solving them.
Whether it’s a small script to simplify one person’s job or a major integration that transforms a department's workflow, the power to build it is now in your hands.


